
COMP9313 Notices
Notices
-
Supp exam time
Posted by Xin Cao Thursday 16 December 2021, 08:51:37 PM, last modified Thursday 16 December 2021, 08:57:40 PM.
The supp exam will be run from 2pm to 6pm on 13/01/2022. To those who will sit the supp exam, please get well prepared for the exam.
Since it is the first time of delivering this course within 10 weeks, I agree that there is a lot of space to improve. For example, the course covers many topics but we did not go deep enough into each. The timeline of the projects is not reasonable, since the deadline of the last project is just one day before the final exam (this never happened in previous years). The tutors should demonstrate the coding practices at the beginning of each lab under the online learning environment.
It is great to receive emails from some of you which told me that the course is helpful and interesting. I have spent great effort on teaching in this term. I tried my best to provide instant feedback in the forum and to reply emails regarding both the lectures and the projects. I even sacrificed my own research time to do the teaching tasks.
Therefore, it is very frustrating for me to see that my teaching evaluation score is lower than the school average. For those who feel unsatisfied with the teaching, in future terms, I hope that you can reflect your concerns and provide feedback during the term, rather than waiting until the end of the term. That would be more helpful to both the teaching team and you.
In addition, some humiliating comments like "I feel like that I am a examiner of IELTS speaking and the lecturer is a nervous examinee" is really mean and rude. Please note that you also have a grammar error in this sentence. I do not think such comments could have any benefit to this course. Anyway, as a non-native English speaker, I will keep improving my English.
Finally, wish you all a Merry Christmas and Happy New Year.
Regards,
Xin
-
Apologies for the inconsistent marks of undergraduate students
Posted by Xin Cao Thursday 16 December 2021, 11:36:19 AM, last modified Thursday 16 December 2021, 01:51:53 PM.
Dear Undergraduate Students,
You may have already received your final mark via email.
However, due to one mistake we made when synchronizing the marks from Moodle to Astra, the mark you have seen in the email is not consistent with that in Moodle.
We will send an email to all of you who are effected by this mistake (if your received mark is lower than Moodle, you will not receive this notification, since the problem has already been fixed in the system and you will see the new mark soon). Please note that your mark as shown in Moodle is the correct one.
We apologies for the mistake and for any inconvenience caused.
Thank you for your understanding.
Kind regards,
Xin
-
The final notice
Posted by Xin Cao Saturday 11 December 2021, 12:31:00 AM.
Dear All,
The marks for Project 3 and the assignment have been released. Please check your mark and contact the tutors before this Sunday if you have any doubt. We need to finalize the marks by this weekend.
I assumed that most of you can obtain the correct results, and thus the marks on correctness is higher than the marks on efficiency. As a result, it turns out a bit unfair for those who had spent great effort on the optimisations but made some minor mistakes in the results. We have tried our best to guarantee fairness, but we may still made some mistakes. Please understand the tutors' hard work considering the large amount of submissions and the complexity of this project.
Most of you did not implement this optimisation: avoid generating duplicated pairs, and compute the similarity on only one common element for each pair. The idea is that: for a pair of records sharing several elements, you only do the computation on the most infrequent element. Thus, on all the other elements, you can safely discard this pair and do not compute their similarity again. This can greatly improve the efficiency.
Finally, remember to delete everything (the files and the clusters) in Dataproc!!! Check your bill and remove your payment method.
I hope that you've enjoyed the course in this term, and I also hope that what you've learned in this course could be helpful to your future career. All the best to you. Keep safe!
Regards,
Xin
-
Exam paper released
Posted by Xin Cao Monday 29 November 2021, 01:58:52 PM, last modified Monday 29 November 2021, 06:43:49 PM.
Dear All,
The exam paper is released already. Please download it at: https://webcms3.cse.unsw.edu.au/COMP9313/21T3/resources/69466 .
If you have any question during the exam, please contact me via email. I will post FAQs in WebCMS3 if necessary.
Please make sure that you submit before the due time, which is 6pm.
Good luck~
Some FAQs:
1. Question 2.(a) It does not matter how you split the lines into words. You can focus on the algorithm design. k is a parameter received from the terminal.
2. Question 4.(ii) Row index starts from 0, since the hash value could be 0. "M is the number of all 2-shingles you have computed from A and B" means that M is the number of unique 2-shingles you have computed from A and B, i.e., the size of the union of A and B's 2-shingles sets.
3. Question 6.(b) There are 5 movies as shown in 6.(a), A, B, C, D, and E. Thus, excluding B, the user vectors have four dimensions: A, C, D, E.
4. Question 3.(b) I am sorry that I made a mistake in the code template. "val edgeList = pairs.map(x => x.split(“,”)).map( x => Edge(x(1).toLong, x(2).toLong, x(3).toDouble))" should be: "val edgeList = pairs.map( x => Edge(x._1.toLong, x._2.toLong, x._3.toDouble))".
5. Due to the mistake of Question 3.(b), you have 20 more extra minutes to work on the exam. The new deadline is 6:20 pm.
6. If you submitted just a few minutes late, that should be fine considering this is an online exam. Please do not send me emails asking about this...
Xin
-
The exam time and one more tip on Project 3
Posted by Xin Cao Sunday 28 November 2021, 01:49:51 AM.
Dear All,
The online exam will run from 2pm to 6pm on next Monday (29/11/2021).
The exam paper will be released at 2:00 pm at the final exam page ( https://webcms3.cse.unsw.edu.au/COMP9313/21T3/resources/69455 ), and you need to submit it through Moodle, similar to the assignments. No late submission is accepted, so please do not wait till the last minute to submit your answers.
Note that this is an individual assessment and you must work on your own. Any plagiarisms will be penalized with a ZERO mark immediately.
Please well manage your time, start from the easier questions, and then come back to the harder ones. If you have any questions, please contact me as soon as possible via email. In addition, you must NOT post anything on the Q&A forum during the exam time.
BTW, I forgot to mention the object name in Project 3's description file. Please name the object as "SetSimJoin", the same as the Scala file name. If you have submitted already, please update the object name and submit again. Thank you for your cooperation.
Regards,
Xin
-
More notes about Project 3
Posted by Xin Cao Thursday 25 November 2021, 12:10:32 AM.
Hi All,
I am sorry that I forgot the "Runtime.jpg" file in the project description file. Please also submit this figure as a separate file in Moodle.
When submitting your code, please remove setMaster("local"). Please also remove the RDD partition numbers, since you may use different number of partitions. To guarantee the fairness of comparing the efficiency, we will run your code in the VM using a single local thread with Spark's default partition.
Please include the job details when taking the screenshot of your job, like below:
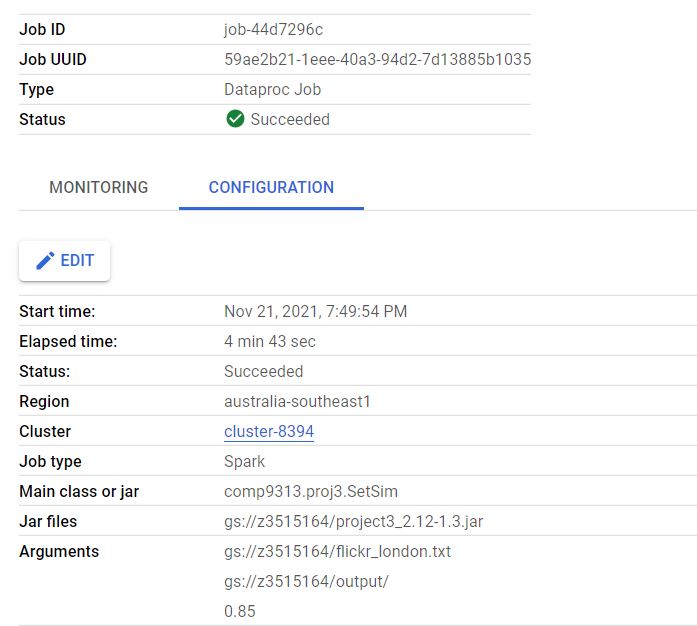
BTW, the solution to Project 2 will be released by tomorrow.
Regards,
Xin
-
This week's Consultation Session
Posted by Xin Cao Tuesday 23 November 2021, 03:54:37 AM.
Dear All,
The consultation session of this week is from 1 pm to 2 pm on Tuesday.
If you have some questions regarding Project 3 and the final exam, you are welcome to attend the session.
BTW, the marks of Project 2 have been released. If you have doubts about your mark, please contact the tutor who marked your submission first.
Regards,
Xin
-
FAQs of Project 3
Posted by Xin Cao Sunday 21 November 2021, 09:12:16 PM, last modified Sunday 21 November 2021, 09:15:34 PM.
Dear All,
I saw a lot of questions recently about project 3. I summarized the questions as below:
1. You do not need to merge the results on Dataproc.
2. If the CPU limit of your account is only 8, you just need to create two clusters: one with 2 worker nodes and the other one with 3 worker nodes. I do not know why the CPU limit is different for us, and I haven't found a solution for this.
3. Check your bill!!! Be careful of how much you have already spent. Remember to terminate the cluster and delete the data in your bucket after you finish your jobs!!! If you have used the $300 credits, you can register with Dataproc using a new email.
4. You CANNOT use LSH to do this project, since that can only obtain approximate results. This project requires exact set similarity join results. Please follow the slides as introduced during the lecture.
5. About the frequency sorting: The currently provided data sets are already sorted (i.e., smaller element IDs means less frequent), but this is not guaranteed in the data sets used for marking. Thus, one more test case without frequency sorting is released to you now.
6. The number of lines in the result file with threshold 0.85 for flickr_london.txt is 23,533,264. I believe most of you can obtain the correct result. So the key issue is how to achieve good performance on Dataproc. Remember that the power of Spark is provided by RDD. If you do not use RDD, your data and computation cannot be distributed.
7. I received some complaints that it costs much longer time on Dataproc assuming no frequency sorting. I think the reason is that your code is not optimized properly enough. The time gap should not be large.
If you are really afraid of running out of your credits, you can run flickr_london.txt without frequency sorting to save the time. Please reflect this in your figure "Runtime.jpg" by adding a note in the figure. However, your submitted program must be able to solve the unsorted data!
8. I tested my code locally in the VM image. Assuming data is sorted and using a single local thread, the run time is about 10 minutes. By doing frequency sorting, the run time is about 15 minutes. If you want to achieve a good mark, your run time should be close to this.
In Dataproc, I only tested in the 6-node cluster, and the job can be completed around 5 minutes (with doing frequency sorting). It is expected that your job can finish within 15 minutes on Dataproc.
9. Someone may see some error messages like: "Broadcasting large task binary with size XXXMB" or "java.lang.InterruptedException". If you job can complete successfully, you can ignore these messages. I also saw such messages when running my job.
10. I can give you some hints to accelerate your program: 0. Do not use SetMaster("local") when running on Dataproc. 1. all element IDs are integers, so do not use string for storing the elements. 2. Please broadcast the frequency lookup table. 3. More partitions of your RDD could be helpful on clusters with more worker nodes. 4. Try to see if your algorithm can avoid generating the duplicated pairs.
11. The efficiency would be marked based on the ranking. We will run your code in both dataproc and the VM to check the efficiency.
BTW, please provide some feedback in myExperience. Any suggestions or comments would be greatly appreciated. Thank you in advance for your cooperation
Regards,
Xin
-
The last assignment released and some other notices
Posted by Xin Cao Thursday 18 November 2021, 05:44:52 AM.
Dear All,
The last assignment has been released, which contains two previous years' exam questions. I will also briefly explain them in today's lecture. The assignment aims to help you get familiar with the style of exam questions. You will have one week to work on it, and it would not take you much time.
Today, Dr. Dong Wen, who just joined our school, will give a guest talk on his research about big graph data management from 2pm to 3pm. Please attend if you are interested in the topic or if you plan to enrol COMP9312 in the next year.
The marks of project 2 will be released in the beginning of the next week.
Please work on project 3 as early as possible. As I mentioned before, the major task in this project is to improve the efficiency. Thus, how to optimize your algorithm and how to achieve excellent performance is your own duty. One hint I can give you is that, think about how to avoid duplicate pairs generation.
Please also register with Google Dataproc as soon as possible. If you meet some problems, please contact us, and we will try to find out a solution for you.
The myExperience surveys are now open. Please provide your invaluable feedback in the system, which would greatly help improving the course contents as well as my teaching in future terms. Thank you in advance for your cooperation.
Regards,
Xin
-
Project 1 Mark Released
Posted by Xin Cao Monday 01 November 2021, 04:20:34 PM.
Dear All,
The marks of project 1 have been released. I will explain the solution of the first project in tomorrow's lecture.
After tomorrow's lecture, if you are still questionable about your mark, please contact the tutor who marked your submission. If they cannot make a decision, I can further check your codes.
Some students were granted an extension for some days, and I've sent the list of names to the tutors. However, it is possible that you still got the late submission penalty. If so, please contact the tutor as well.
For project 2, please work on it as soon as possible. Similar to project 1, first work on labs 5-7. These lab problems aim to help you solving the project problems.
You can also use Eclipse to write and debug your codes, and the instruction is at here: https://webcms3.cse.unsw.edu.au/COMP9313/21T3/resources/68851
Regards,
Xin
-
Some FAQs about Project 1
Posted by Xin Cao Friday 15 October 2021, 11:54:41 PM.
1. I saw some requests for more test cases in the forum. Thus, one more test data is provided. If you use Java, the running script is also provided, including packaging your java files and run your jar file on Hadoop (please change the document number and the reducer number accordingly).
2. Please use the pre-installed Hadoop at ~/hadoop. Lab 1 only aims to let you know how to install and configure Hadoop. Please delete the ~/workdir folder after you compete Lab 1, as well as the corresponding configurations in ~/.bashrc.
3. Before you run mrjob code on Hadoop, please start both HDFS and YARN. Please check if you have configured YARN correctly by following the instructions of Lab 1, including two files: $HADOOP_CONF_DIR/mapred-site.xml and $HADOOP_CONF_DIR/yarn-site.xml.
4. The "\t" means the tab character, not a string "\t". Because one tab character may take 4 or 8 space characters, in the editor and in the terminal the texts may be displayed differently.
5. Please try your best to debug your code, and then ask questions. You can first test your code locally, and then run on Hadoop. Note that it is very possible that your code can generate correct results locally but fails on Hadoop. There must be something wrong due to the key partitions. In mrjob, you can first test your mapper and then test your reducer. To test the mapper, you can write a simple reducer which writes the mapper output directly to the reducers. By doing so, you will be able to know if your mapper can send the key-value pairs to the reducers as expected. After the mapper is OK, you can proceed to test your reducer.
6. A variable defined in mapper_init/reducer_init and mapper/reducer has different scopes. If it is defined in mapper/reducer, it can only be seen within this mapper function call for the current input. If it is defined in mapper_init/reducer_init, it can be seen by all mapper/reducer functions within each mapper/reducer.
7. It is strongly recommended to complete the two problems in Lab 4 first, and then work on the project. Otherwise, you will meet many problems during working on the project.
-
Some tips about the first project
Posted by Xin Cao Saturday 09 October 2021, 02:06:13 AM.
Dear All,
You still have one weekend plus one week to work on the first project.
1. Lab 4 is released already, which will help you writing codes for project 1, especially on how to use the partitioner and comparator class in mrjob (if you use java, the lab provides you some practices on defining a custom partitioner and defining an order for your keys).
If you do not know how to work on the project now, please first complete the problems in Lab 4, and then you will have better ideas on solving the project problem.
2. It is allowed to pass the number of documents as an argument in the python version of the project. To make it fair, if you use java, you are also allowed to do so. I have updated the project description for the java version. Please download the new document.
3. I've made a mistake in slide 21 of Chapter 3.1 on how to use the partitioner class in mrjob. I have updated that slide, and please download a new version as well.
Regards,
Xin
-
Change of the consultation time
Posted by Xin Cao Saturday 02 October 2021, 11:24:38 PM.
Dear All,
Due to that the previous consultation time collides with some students' lab session, the consultation time will be changed from 4pm-5pm on Thursday to 12pm-1pm on Tuesday (after the lecture) from the next week.
The project will be released on next Monday, and you will have two weeks working on it. I suggest you first complete the lab programming activities and then work on the project.
Please always remember to download a new version of the lecture slides after each lecture, since I may do some edits (such as correcting the typos or adding a few new slides).
Regards,
Xin
-
The VM image download address
Posted by Xin Cao Wednesday 15 September 2021, 03:22:16 PM.
Dear All,
As I mentioned in the first lecture, please download the VM image within this week, since you will need to use it in the next week's lab.
You can download from:
https://drive.google.com/file/d/1SaAaQa8f17SsOixq8mNI6R6Dn2mMDYkp/view?usp=sharing , or
https://drive.google.com/file/d/1eeVqc7yK3xFPRtb09plJcK_Sc4yYuBFz/view?usp=sharing .
For students living in China now, please first connect to the UNSW VPN and then download the image. If it still does not work for you, you may also try to download from Mega (but you may need to download the mega client first): https://mega.nz/file/vuAUGDZC#KzdzjEictGMdpYlMaSKwHS9mveovrd_yUwg_8nL-ZBg .
Then, follow the instructions here to import and configure the image.
Regards,
Xin
-
The first online lecture
Posted by Xin Cao Monday 13 September 2021, 03:14:28 PM.
Dear All,
The first lecture will be delivered online from 10am to 12pm tomorrow.
Please login Moodle to access the course link.
In case you cannot find it, you can also access through https://au.bbcollab.com/guest/a12f1733665649d5bc66af883dcf1a48 .
Looking forward to seeing you all tomorrow.
Regards,
Xin
-
Welcome to COMP9313
Posted by Xin Cao Thursday 09 September 2021, 01:26:30 AM.
Dear COMP9313 Students,
Welcome to COMP9313!
The outline of the course is now available, please see " Course Outline " in the left panel .
Our first lecture is on Tuesday in Week-1, and the labs will begin in Week-2. Due to COVID-19, all course activities will be online.
Regards,
Xin